Science + Society
Unraveling
the JPEG
Unraveling
the JPEG
the JPEG
Unraveling
the JPEG
It’s easy to take for granted that you can send a picture to a friend without worrying about what device, browser, or operating system they’re using, but things weren’t always this way. By the early 1980s, computers could store and display digital images, but there were many competing ideas about how best to do that. You couldn’t just send an image from one computer to another and expect it to work.
To solve this problem, the Joint Photographic Experts Group (JPEG), a committee of experts from all over the world, was established in 1986 as a joint effort by the ISO (International Organization for Standardization) and the IEC (International Electrotechnical Commission)—two international standards organizations headquartered in Geneva, Switzerland.
JPEG, the group of people, created JPEG, a standard for digital image compression, in 1992. Anyone who’s ever used the internet has probably seen a JPEG-encoded image. It is by far the most ubiquitous way of encoding, sending and storing images. From web pages to email to social media, JPEG is used billions of times a day—almost every time we view or send images online. Without JPEG, the web would be a little less colorful, a lot slower, and probably have far fewer cat pictures!
This article is about how to decode a JPEG image. In other words, it’s about what it takes to convert the compressed data stored on your computer to the image that appears on the screen. It’s worth learning about not just because it’s important to understand the technology we all use everyday, but also because, as we unravel the layers of compression, we learn a bit about perception and vision, and about what details our eyes are most sensitive to.
It’s also just a lot of fun to play with images this way.
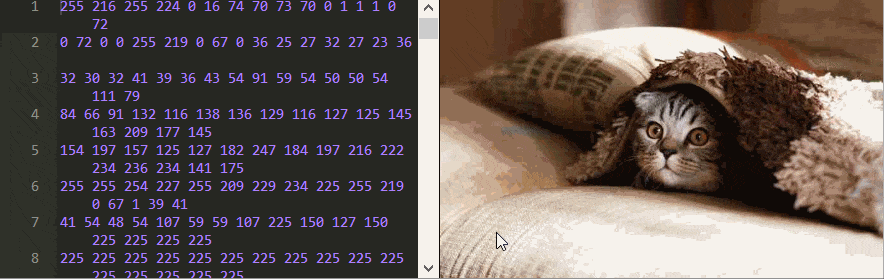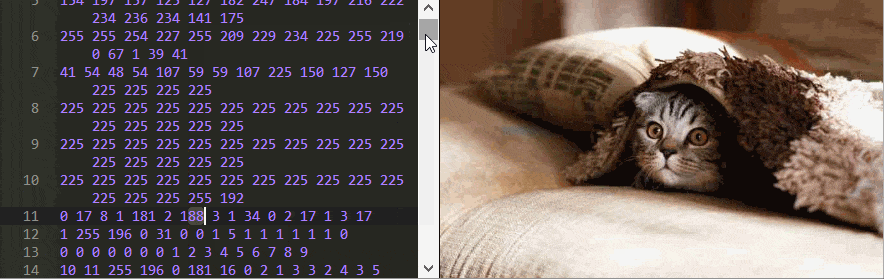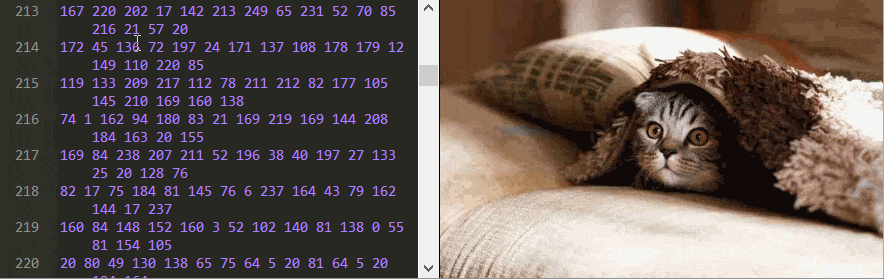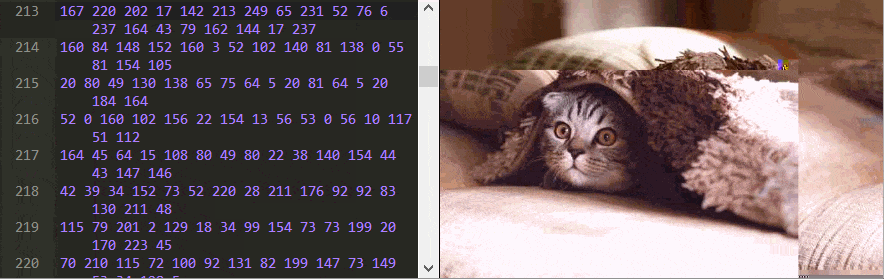
Peering Inside a JPEG
Everything on a computer is stored as a series of binary numbers. Typically, these bits, the zeros and ones, are arranged in groups of eight, known as bytes. When you open a JPEG image on your computer, something (the browser, your operating system, or something else) has to decode the bytes to recover the original image as a list of colors that can then be displayed.
By opening an image in a text editor, you’ve confused the computer, in the same way you confuse your brain when you rub your eyes too hard and start to see blotches of dimness and color!
These blotches you see—known as phosphenes—don’t come from any light stimulus, nor are they hallucinations made up in your mind. They arise because your brain assumes that any electrical signal arriving through the nerves in your eye is conveying light information. The brain needs to make this assumption because there’s no way to know whether a given signal is sound, sight, or something else. All the nerves in your body carry exactly the same type of electrical pulse. When you apply pressure by rubbing your eyes, you’re sending non-visual signals that trigger the receptors in your eye, which your brain interprets—incorrectly, in this case—as vision. You can literally see the pressure!
It’s fun to think about how similar computers are to our brains, but this is also a useful analogy because it illustrates how much the meaning of data—whether carried through a body by nerves or stored in a computer—relies on how you interpret it. All binary data is made up of ones and zeros, basic components that could be conveying any kind of information. Your computer often guesses how to interpret it using clues, like the file extension. Here we’ve forced it to interpret it as text, because that’s what a text editor expects.
To understand how a JPEG image is decoded we need to see the original signals themselves—the binary data. This can be done with a hex editor
There’s a lot you can learn just from playing around with this editor. For example, can you figure out the order the pixels are stored in?
Something strange in the example above is that changing some numbers doesn’t seem to impact the image at all, while setting the 17 on line one to 0 completely ruins the image! Other actions, like setting the 7 on line 1988 to 254 change the color, but only for subsequent pixels.

Perhaps what’s most peculiar is that some numbers change not just the color but the shape of the image as well. Change the 70 in line 12 to 2 and look at the top row of the image to see what I mean. No matter what JPEG image you’re using, you’ll always find these mysterious checkerboard patterns when editing the bytes.
It’s hard to decipher how the image can be reconstructed from these bytes by playing around like this, because JPEG compression is actually composed of three different compression techniques, which are applied in successive layers. We’ll look at each of these layers of compression separately to unravel this mysterious behavior we’re seeing.
The three layers of JPEG compression
- Chrominance Subsampling
- Discrete Cosine Transform & Quantization
- Run-Length, Delta & Huffman Encoding
To give you an idea of the scale of this compression, notice that the image above is represented using exactly 79,819 numbers, which makes it about 79 kilobytes. If it were stored with no compression, three numbers would be needed for each pixel—one for each of the red, green and blue components. That would mean a total of 917,700 numbers, or about 917 kilobytes. With JPEG compression, the resulting file is over ten times smaller!
In fact, this image can be squeezed into far fewer bytes. Below is the image next to a version of it that was compressed down to just 16 kilobytes, which makes it fifty-seven times smaller than the uncompressed version would be!

If you look closely you’ll see that these images are not identical. Both are JPEG-encoded images, but the one on the right is much smaller in terms of file size. It also doesn’t look as nice (notice how blocky the colors look in the background). This is why JPEG is known as a lossy compression technique; the image changes and loses some detail as a result of the compression.
1. Chrominance Subsampling
Here’s the image with just the first layer of compression applied.
It’s a little more straightforward to decipher now. It’s almost a simple list of colors, where each byte changes exactly one pixel, and yet it’s already almost twice as small as the uncompressed image (which would be around 300 kb for this smaller size). Can you guess why?
You can tell that these numbers don’t represent the standard red, green and blue components because replacing all the numbers with 0 turns the image green (as opposed to black).
This is because these bytes represent the Y (brightness), Cb (relative blueness), and Cr (relative redness) of the image.
Why not just use RGB? After all, that’s how most modern screens work. Your monitor can display any color by turning on red, green and blue lights at various intensities for each pixel. White is displayed by turning on all three colors at full brightness, while black is displayed by turning them all off.
That’s also very similar to how human eyes work. The color receptors in our eyes known as “cones” are split into three types, each of which is mostly sensitive either to red, green, or blue. Rods, the other type of receptor we have in our eyes, can only detect changes in brightness, but they’re far more sensitive. We have about one hundred and twenty million rods in our eyes, compared to a measly six million cones.
This means that our eyes are much better at detecting changes in brightness than they are at detecting changes in color. If we can separate the color from the brightness, we can remove a bit of the color without anyone noticing. Chrominance subsampling is the process of representing an image’s color components at a lower resolution than its luminance components. In the example above, each pixel has exactly one Y component, while each discrete group of four pixels has exactly one Cb and one Cr component. So the image contains only a quarter as much color information as it originally did.
This is why removing one number from the editor above completely ruins the color. Here, the components are stored
There’s nothing in the JPEG specification that says you must use YCbCr. Most JPEG images you’ll find use it because it tends to produce higher quality images after subsampling compared to RGB. You don’t have to take this for granted though. You can see for yourself in the grid below what it looks like to subsample each component individually across RGB as well as YCbCr.
Move slider to adjust the amount of subsampling applied.
Subsampling the Y component (bottom left) has the greatest effect on the image quality. Even a tiny bit is already noticeable. You can move the slider to see how removing a greater percentage of each component affects the image.
Converting an image from RGB to YCbCr doesn’t make the file size any smaller, but it does make it easier to find less noticeable details to remove. It’s that second step where the actual lossy compression happens. This idea of finding new ways to represent data to make it more compressible is at the heart of what the next layer does.
2. Discrete Cosine Transform & Quantization
This layer of compression is largely the defining feature of JPEG. After the colors are converted to YCbCr, the components are compressed individually, so we can focus on just the Y component for the rest of the article. Here’s what the bytes for the Y component look like with this layer applied.
At first glance, this seems like very poor compression. There are 100,000 pixels in this image, and yet it takes 102,400 numbers to represent the luminance of each pixel—that’s worse than not compressing it at all!
But notice that most of these values are 0. In fact, all of these trailing zeros can be removed with no change to the image. This leaves only about 26,000 numbers, which makes it about four times smaller!
In this layer lies the secret to the checkerboard patterns. Unlike the other effects we’ve seen, the appearance of these patterns is not a glitch. They are in fact the building blocks of the entire image. Every line in the editor above contains exactly 64 numbers, known as the Discrete Cosine Transform (DCT) coefficients, which correspond to intensities of 64 unique patterns.
These patterns are formed out of cosine waves. Here’s what a few of them look like:

Below is an image that shows all 64 of them individually.
These patterns are special because they form a basis for 8x8 images. If you’re not familiar with linear algebra, what that means is that any 8x8 image, anything at all that you can imagine, can be made out of these specific 64 patterns. The Discrete Cosine Transform is the process of breaking up the image into 8x8 blocks and converting each block into a combination of these 64 coefficients. Here’s how you would form a circle by combining these patterns, or the cat’s face. You can click here to go back to the grid of 64 patterns.
It seems like magic to say that any image can be represented using 64 specific patterns. But this is the same thing as saying any location on the Earth can be represented using only two numbers: longitude and latitude. We often treat the surface of the Earth as two-dimensional, so only two numbers are needed. An 8x8 image is sixty-four-dimensional, so we need sixty-four numbers.
In terms of compression, it’s not obvious how this helps us. If we need sixty-four numbers to represent an 8x8 image, why is this better than storing the sixty-four luminance components? We do it for the same reason we converted from the three numbers of RGB to the three numbers of YCbCr: it allows us to remove detail that’s less noticeable.
It’s hard to see exactly what the details that are removed in this compression step look like because JPEG only applies the Discrete Cosine Transform to blocks of 8x8 pixels at a time. However, there’s no reason we can’t apply it to the whole image. Here’s what it looks like to apply the DCT to the Y component of the entire image:
We can remove over 60,000 numbers from the end with almost no noticeable change. But notice that if we set just the first five numbers to zero (ignoring the first because it just makes the image darker) there’s already an obvious difference.
The numbers at the beginning represent the lower frequency changes in the image, which our eyes are better at detecting. The numbers towards the end represent the higher frequency changes, which are harder for us to see, so we don’t notice when they’re gone. To see “what our eyes can’t see”, we can isolate these high frequency details by setting the first 5,000 numbers to zero.
What you’re looking at here is all the areas of the image that have the greatest change from one pixel to the next. The cat’s eyes, whiskers, fuzzy blanket and shadows in the bottom left corner all stand out. This can be taken even further, to setting the first 10,000 numbers to zero; 20,000; 40,000 or 60,000.
These high frequency details are what JPEG removes during this compression step. Converting the colors to the DCT coefficients is not a lossy operation. It’s the quantization step that’s lossy, where values that are high frequency, close to zero, or both, are removed. When you select a lower quality setting when creating a JPEG image, it increases the threshold for how many of these values are removed, which leads to a smaller file size but a blockier image. This is why the version of the image in the first section that was 57 times smaller looked blocky. Each 8x8 block was represented by far fewer DCT coefficients compared to the higher quality version.
Just for fun, here’s what it looks like using just 24,000 numbers, or just 5000 numbers. Pretty blurry, but almost recognizable!
3. Run-Length, Delta & Huffman Encoding
All the compression steps so far have been lossy. This last layer, by contrast, is lossless. It doesn’t remove any information, but it does make the file size significantly smaller.
How do you compress something without throwing away any information? Think about how you would represent a simple solid black image.
JPEG uses about 5,000 numbers to represent this, but we can do much better. Can you think of an encoding scheme to represent this image using as few bytes as possible?
The smallest I could think of was four bytes: three to specify the color and one to specify how many pixels have this color. The idea of expressing all repeated values concisely this way is called run-length encoding. It’s lossless because we can recover the encoded data exactly as it was before.
The file size of the solid black JPEG image is much bigger than four bytes because remember that in the DCT layer, the compression is applied to 8x8 blocks at a time. So at minimum we’ll need one DCT coefficient for each 64 pixel block. We only need one because instead of storing one DCT coefficient followed by 63 zeros for this image, run-length encoding allows us to just store one number and say “the rest are zero”.
Delta-encoding is the technique of storing each byte as a relative value compared to something before it instead of storing its absolute value. This is the reason editing certain bytes will change the color for all subsequent pixels. For example, instead of storing:
12 13 14 14 14 13 13 14You would start with 12, and from there, just store how much you need to add or subtract to get the next number. So once delta-encoded the sequence above becomes:
12 1 1 0 0 -1 0 1Once again, the transformed data is not any smaller than the original, but it is more compressible. Applying delta encoding before run-length can help a lot, while still remaining a completely lossless compression step.
Delta encoding is one of the few techniques that is applied outside the 8x8 blocks. Out of the 64 DCT coefficients, the first one is just a constant wave function (you see it as a solid color). It represents the average brightness of each block for the luminance components, or the average blueness for the Cb components etc. This first value in each DCT block is called the DC value, and each DC value is delta-encoded relative to the ones before it. So changing the brightness of the very first block will affect all blocks in the image.
This all leaves just one final mystery: how can changing just a single number completely wreck the image? This was not a property of any of compression layers so far. The answer lies in the JPEG header. It’s the first 500 or so bytes that contain metadata about the image, like its width and height, and has been omitted from all the byte editors so far.
Below is the original image with the header included.
Without the header, it’s practically impossible (or at least very difficult) to decode the JPEG image. It would be as if I was trying to describe a painting to you, and I started to invent words to communicate what I saw. It’s probably going to be a very concise description, since I can define the words to mean exactly what I want to communicate, but it would be meaningless to anyone other than me.
This may sound ridiculous, but this is exactly what’s going on here. Every single JPEG image is compressed with a code that’s specific to this particular image. These codes are defined in a dictionary stored in the header. This technique is called Huffman encoding, and the dictionary is called a Huffman table. This table is marked in the header by two bytes: 255 followed by 196. Each color component may have its own Huffman table.
Changes to these Huffman tables will have the most dramatic effects on any image. Changing the second 1 to 12 on line 15 is a good example. Changing anything after the 125 on that line works too.
The Huffman tables have such a dramatic effect on the image because they tell us how to read the individual bits. So far we’ve just been dealing with the binary numbers in decimal. This hides the fact that if you want to store the number 1 in a byte, it would look like 00000001, because each byte must have exactly eight bits even if it only needs one bit.
This is potentially a huge waste of storage if you have a lot of small numbers. Huffman encoding is a technique that allows us to relax this requirement that each number must occupy eight bits. That means if you see the two bytes:
234 115Based on the Huffman table, these could actually be three values. To extract them, you’ll need to first break them into their individual bits:
11101010 01110011One neat trick you can do with this knowledge is strip out the header from a JPEG image and save it separately. You’re effectively making it so only you can read it. Facebook actually does this to make JPEG images even smaller.
Another thing you can do is change the Huffman table just slightly. To anyone else, it looks like a corrupted image. But only you would know the magic edit needed to fix it.
Then follow the table to figure out how to group them. For example, it could be the first six bits (111010) which is 58 in decimal, followed by another five bits (10011) which is 19 and finally the last four bits (0011), which is three.
So to summarize, what all does it take to decode a JPEG image? You need to:
- Extract the Huffman table(s) from the header and decode the bits.
- Extract the Discrete Cosine Transform coefficients for each color/luminance component, for each 8x8 block, by undoing the run-length and delta encodings.
- Combine the cosine waves based on the coefficients to get back the pixel values for each 8x8 block (this is known as the inverse Discrete Cosine Transform).
- Scale up the chrominance components if they were subsampled (the header has this information).
- Convert the resulting YCbCr of each pixel to RGB.
- Display the image!
That’s a lot of work to view a simple cat picture! But what I love about this is that you can see how JPEG is a very human-centric technology. It relies on the quirks of our perception to achieve compression rates far greater than is possible with general purpose techniques. And now that you understand how JPEG works, you can imagine how many of these techniques can be extended to other domains. For example, applying delta-encoding in video can produce a huge file size reduction since there are often areas that don’t change at all between frames (such as the background).
All the code for this article is open source and includes instructions on replacing the images in these byte editors with your own.